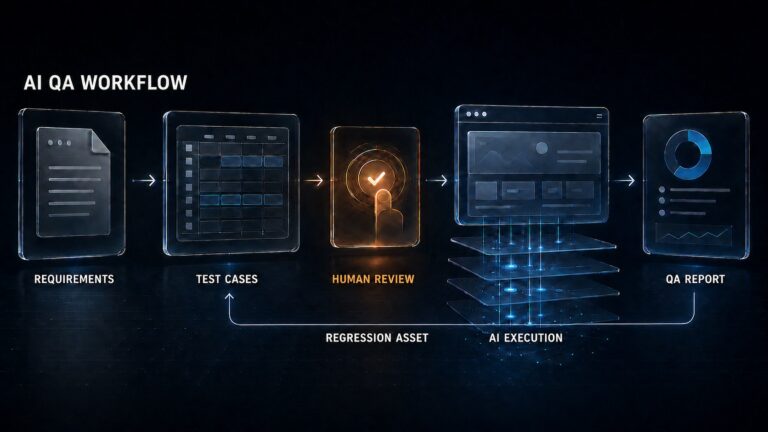
AI QA Workflow 설계: 기획서에서 리포트까지
Claude Code와 Antigravity를 같은 기준으로 적용하며 확인한 설계 기준과 한계 지난 글에서는 기획서와 프롬프트를 기반으로 Antigravity에 브라우저 QA를 위임하는 구조를 시험했습니다. 당시 Antigravity는 화면 검수에 그치지 않고 CSP 차단이나 정규식 파싱 누락 같은 실패 원인까지 분석해 리포트로 정리했고, 글 말미에 같은 서비스를 Claude Code로도 검증해 보겠다고 적었습니다. 이번 글은 그 후속입니다. 다만 진행해 보니 도구…