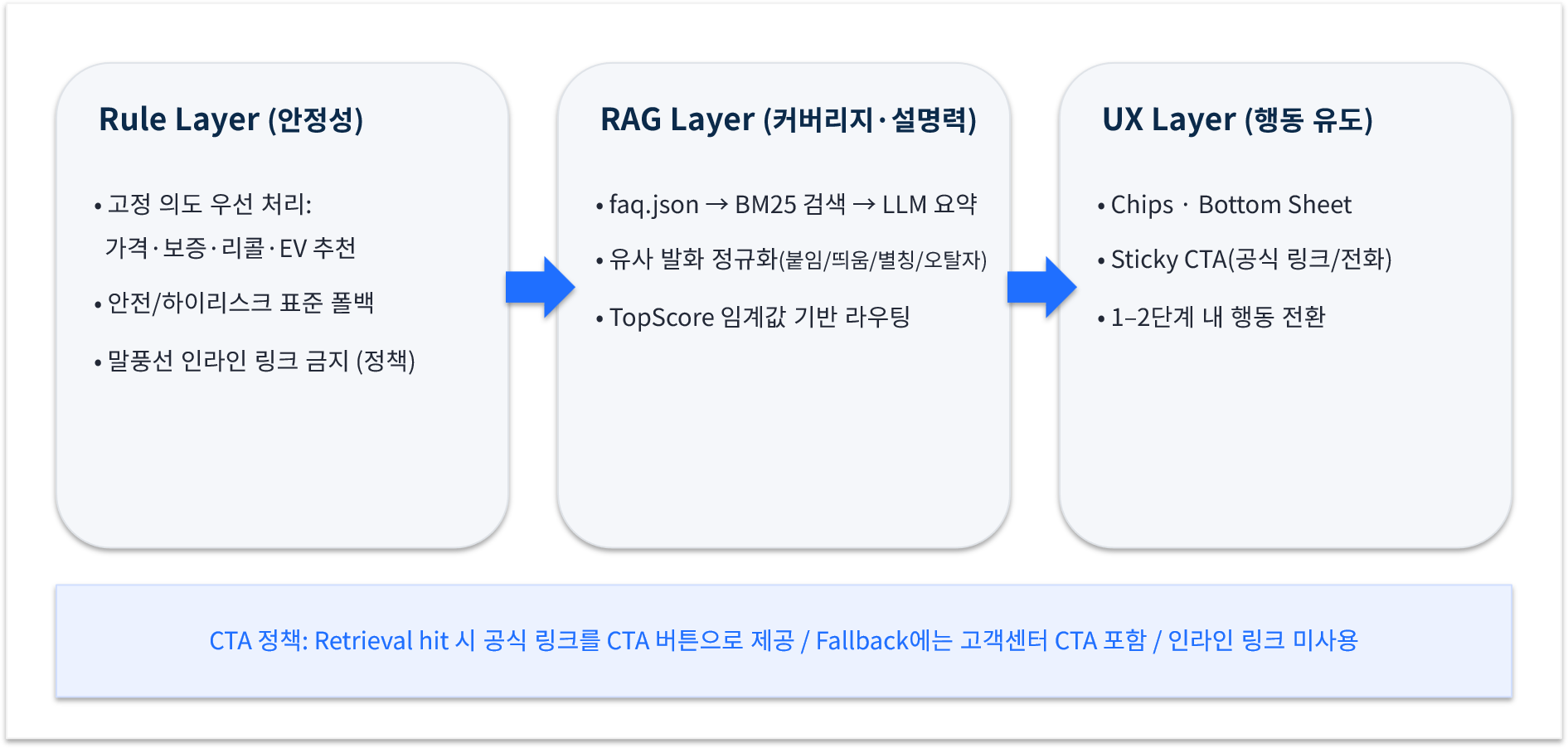
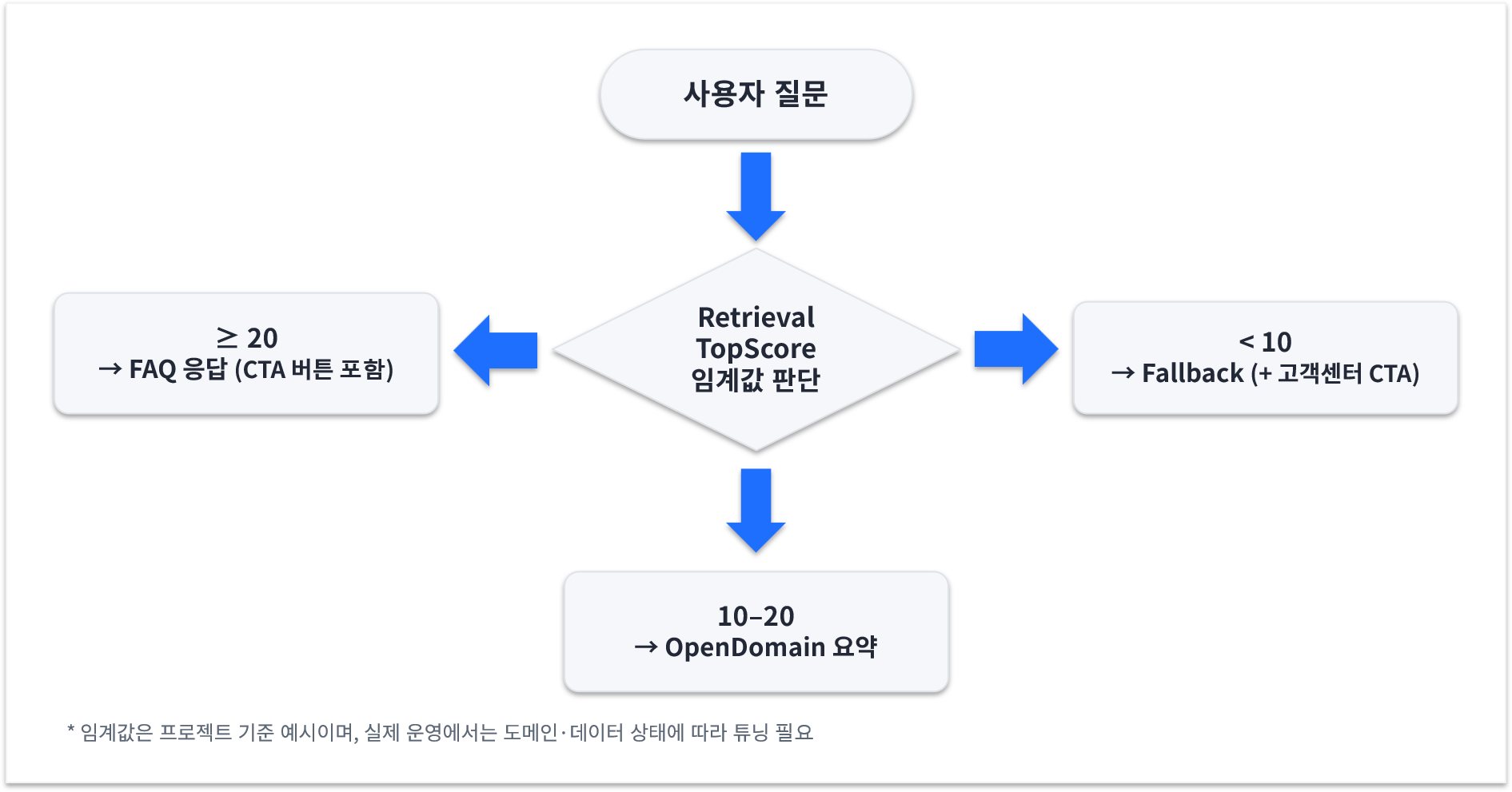
부제: 더 좋은 응답을 쉽게 얻는 법
LLM을 쓰다 보면 누구나 한 번쯤 이런 경험을 합니다.
- “어제는 잘하더니 오늘은 왜 이렇게 엉뚱하게 답하지?”
- “GPT가 작업 중간에 뭔가 잃어버린 것 같은데?”
- “이렇게 스펙을 정리했는데 왜 다른 걸 이해하지…?”
이 차이를 만드는 핵심 원인은 프롬프트를 어떻게 입력 혹은 설계했느냐입니다.
같은 모델에게 요청해도 결과가 다르게 나오는 이유죠.
이 글에서는 ‘프롬프트 vs 프롬프트 엔지니어링’의 차이를
가장 쉽고 실용적인 관점에서 정리해보겠습니다.
🧩 1. 프롬프트란 무엇일까요?
프롬프트는 AI에게 주는 요청(Instruction)입니다.
즉, “이걸 해달라”고 전달하는 단순 명령입니다.
예를 들면:
- “이 문서를 요약해 주세요.”
- “서비스 기획서를 작성해 주세요.”
- “아이온2 전투 시스템을 설명해 주세요.”
이렇게 단순하게 입력해도 모델은 꽤 많은 일을 해냅니다.
하지만 문제는 결과가 일정하지 않다는 점입니다.
바로 이 지점에서 엔지니어링이 필요해집니다.

🏗️ 2. 프롬프트 엔지니어링이란?
프롬프트 엔지니어링은
AI가 더 좋은 결과를 안정적으로 내도록 입력을 설계하는 기술입니다.
단순히 길게 쓰거나 어렵게 쓰는 게 아니라,
- 목적
- 구조
- 맥락
- 데이터
- 출력 형식
등을 명확하게 설계해 모델이 헤매지 않도록 안내하는 작업입니다.
그리고 중요한 사실이 있습니다.
프롬프트 엔지니어링은 개발자 기술이 아닙니다.
언어로 ‘설계’를 하는 모든 사람에게 필요한 스킬입니다.
PM·마케터·기획자·에디터·컨설턴트…
LLM을 쓰는 누구나 매일 부딪히는 실용 기술입니다.
🎯 3. 왜 굳이 프롬프트 엔지니어링을 해야 할까요?
저도 초기에는 이렇게 생각했습니다.
“GPT가 똑똑한데 굳이 복잡하게 설계할 필요가 있나?”
하지만 실제 업무에서 깊게 활용해보니 명확한 이유가 있습니다.
✔ 결과 품질이 매번 다르다
작은 표현·순서 차이만으로도 큰 품질 차이가 납니다.
✔ 모델은 부정문·복잡한 문장·중간부 누락에 취약
Lost in the Middle(중간 내용 삭제)은 LLM의 고질적 문제입니다.
✔ 엔지니어링을 하면
- 더 정확하고
- 더 빠르고
- 더 저렴하고
- 재사용 가능한 자동화 도구가 됩니다.
결국 목적은 하나입니다.
더 좋은 결과를 얻기 위해서.
더 쉽게, 더 안정적으로.
🧱 4. 프롬프트 엔지니어링의 핵심 4요소
이 4요소는 Anthropic Claude Prompt Engineering Guide,
OpenAI Prompting Overview,
Google Cloud Prompt Engineering Guide에서 공통적으로 사용하는 구조입니다.
각 요소의 의미를 1줄로 정리하면 다음과 같습니다.
① Instructions (지시)
모델에게 “무슨 작업을 해야 하는지” 명확히 전달하는 부분.
예)
- “아래 문서를 3줄로 요약해 주세요.”
② Input Data (데이터)
모델이 실제로 처리해야 하는 텍스트·표·코드 등 입력 데이터.
예)
- 분석할 문서 본문
- 사용자 로그
- 텍스트 조각
③ Context (맥락)
작업이 수행되는 배경·조건·관점을 설명하는 부분.
예)
- “PM 관점에서 설명해 주세요.”
- “전문가 톤을 유지해주세요.”
④ Output Indicator (출력 지시문)
모델이 어떤 형태로 결과를 내야 하는지 구조·형식을 명시.
예)
- “표 형식으로 작성해 주세요.”
- “JSON으로 출력해 주세요.”
- “한 줄당 20자 이하로 써 주세요.”
…
이 네 가지를 포함해 프롬프트를 작성하면 품질과 재현성이 크게 향상됩니다.
✏️ 5. 엔지니어링 팁 — 이것만 기억해도 반은 성공합니다
(각 항목에 좋은 예시(O) / 나쁜 예시(X) 포함)
✅ 1) 부정문 최소화
LLM은 부정문을 자주 오해합니다.
(X) 나쁜 예시
“문체는 절대 변형하지 말고 요약해 주세요.”
→ ‘변형하지 말고’를 무시하거나 반대로 이해할 위험↑
(O) 좋은 예시
“문체는 그대로 유지하고, 핵심 내용만 요약해 주세요.”
→ 긍정문 기반 → 오해 없음
✅ 2) 구조화된 프롬프트 사용
모델은 구조를 좋아합니다.
(X) 나쁜 예시
“전투, 경제, 보상을 포함해서 게임 시스템을 자세히 설명해 주세요.”
→ 누락 or 순서 혼란 가능
(O) 좋은 예시
출력 구조:
- 전투 시스템(3줄)
- 경제 구조(표)
- 보상 구조(장점/리스크 2줄씩)
→ 모델이 “틀”대로 작성 → 안정적 출력
✅ 3) 출력 형식을 먼저 정하기
(X) 나쁜 예시
“이 글의 핵심 내용을 알려주세요.”
→ 모델이 임의 판단 → 길이·형식·순서 불안정
(O) 좋은 예시
“아래 문서를
- 3줄 요약
- 불렛 포인트
- 한 문장 20자 이하
형식으로 정리해 주세요.”
→ 품질·일관성 급상승
✅ 4) 짧고 명확하게
긴 설명은 사람도 AI도 이해하기 어렵습니다.
(X) 나쁜 예시
“배경이 이런데, 그래서 제가 원하는 건 이런 거고… 아무튼 잘 정리해 주세요.”
(O) 좋은 예시
“아래 기사를 PM 관점에서 3줄로 요약해 주세요.”
→ 명확·간결·정확
🔮 6. 앞으로는 GPT에게 ‘설계’까지 맡기는 시대
프롬프트 엔지니어링의 최신 방향은
“프롬프트를 사람이 직접 설계하는 시대가 끝나가고 있다”입니다.
이제는 이렇게 요청하는 것이 더 효율적입니다.
“GPT, 이 작업을 위한 최적의 프롬프트를 먼저 설계해 주세요.”
사람은 요구사항만 제시하고,
프롬프트의 구조·형식·샘플·맥락은 모델이 설계하는 시대입니다.
🧭 7. 마무리
프롬프트 엔지니어링은 어렵지 않습니다.
본질은 “좋은 질문을 구조적으로 만드는 기술”이며,
이를 통해 더 좋은 응답을 쉽게 얻을 수 있습니다.
이번 1부에서는 개념을 정리했습니다.
2부에서는 실전 Before/After 비교를 공개하겠습니다.
📘 다음 글 예고
2부: 프롬프트 엔지니어링은 GPT에게 맡기세요 — 실전 Before/After 3선
내용 구성:
- AI/RAG 평가 기준 자동 생성
- 데이터 정제 + 시각화 레포트 생성
- 서비스 기획 문서 자동 생성
세 가지 실무 예제를 통해 프롬프트 엔지니어링의 효과를 보여드립니다.