
추석 연휴 간,
개인 프로젝트로 진행한 하이브리드 챗봇 데모를 공개합니다.
Rule의 안정성과 LLM의 확장성을 결합하여,
연휴 기간 동안 바이브코딩 방식으로 직접 구축하고 다듬어 보았습니다.
(※ 현대자동차 공식 챗봇과 무관합니다.)
🎬 Hook: 1분 데모 + 최종 평가 표
👉 Demo: hyundai-chatbot-demo.vercel.app
※ 참고: Vercel 빌드 환경에서는 일부 RAG 질의(띄어쓰기·유사명칭·오탈자 등)의 인식률이 Stackblitz 실험 환경보다 낮게 나타날 수 있습니다.
본 영상은 Stackblitz 기준으로 촬영되었으며, 동일 코드 기반으로 Vercel에서도 대부분 정상적으로 작동합니다.

1️⃣ 왜 만들었나 (Why)
이번 데모는 바이브코딩을 통한 챗봇 구현 프로젝트의 일환으로, 차량 구매 목적의 실제 사용자 시나리오에서 출발했습니다.
기존 챗봇의 경우 기본 정보 제공은 충분했지만, 구매·시승·상담 등 다음 행동으로 자연스럽게 이어지는 흐름은 더 보완될 여지가 있었습니다.
목표는 기존 시스템을 비판하는 것이 아닌, “정보 전달 → 행동 전환” 간격을 줄이는 플로우 설계였습니다.


- 구매 목적 사용자 시나리오의 개선 포인트
- 견적/시승 문의까지 이동 단계가 비교적 길어지는 구간
- 외부 페이지 이동 시 대화 맥락이 단절되는 지점
- 동일 메뉴/버튼 반복 노출로 인한 탐색 피로
이에 따라 데모는 “FAQ 요약 + 공식 링크(CTA) + 최소 단계 전환”을 원칙으로, 사용자가 질문하면 필요 행동까지 즉시 연결되고 순환되는 경험을 지향했습니다.
2️⃣ 어떻게 만들었나 (How)
Part 1. 분석 & 전략
- 가설
- 목표 행동(구매·시승·AS)까지 경로 단축과 링크/CTA 무결성이 사용자 만족도와 목표(KPI) 전환에 결정적이라고 가정
- 또한 LLM 측면에서 유사 발화 대응력(띄어쓰기·별칭·오탈자)이 실사용성에 큰 영향을 준다고 가정
- 분석
- 실제 공식 사이트 캡처·메뉴 트리 분석
- Top FAQ 및 유사 발화 수집&정규화
- 링크 유효성 및 도메인 점검
- 전략
- 플로우 단순화(Simplify Flow) → 메뉴 통합, CTA 중심 설계, 1~2단계 내 해결
- 지속적인 연결(Connect Experience) → 핵심 정보는 대화 내 제공, 필요 시에만 외부 링크
- 데이터 최신화(Keep Data Fresh) → 공식 FAQ 247 + 추가 Top 50 정비하여 반영 ( 지식 강화로 RAG 품질 안정화/고도화에 기여)
Part 2. 설계 & 개발
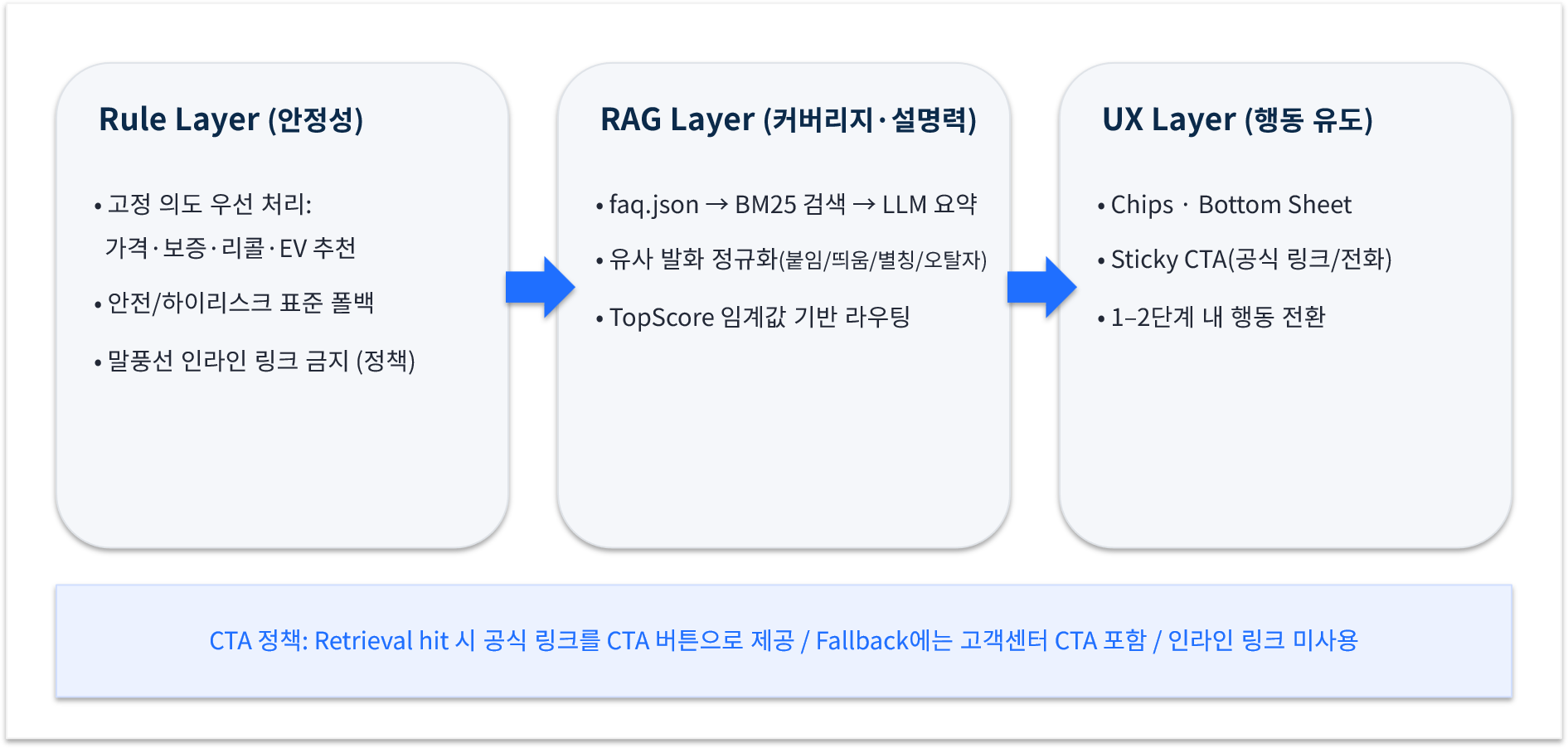
- 아키텍처(Front-only Hybrid)
- Rule Layer: 가격·보증·리콜·EV 추천 등 고정 의도 우선 처리
- RAG Layer: faq.json + BM25 검색 → LLM 요약
- UX Layer: 칩(Chips), 바텀시트, Sticky CTA(공식 링크/전화)

- R1 → R2 → R3 개선 사이클
- R1 (Prototype): Rule 70~80% + RAG 기본(가능성/흐름 우선)
- R2 (Tuning): Rule 100% + 현대차 공식 FAQ 크롤링 반영 + BM25 교체, 유사 발화 정규화, 자동 테스트 루틴 구축
- R3 (QA/Deploy): 자동/수동 라벨 교차검증, CTA·Fallback 보강 → 최종 평가 표 기준 전 항목 Pass
Part 3. 자동 테스트 & QA
- 테스트 루틴
- 콘솔 기반 runBatch() 자동 테스트 → 수동 라벨링으로 최종 판정
- 라벨 분포 보정(R1을 예시)


- 자동: Good 40 / Fair 120 / Bad 136
- 수동(최종): Good 183 / Fair 2 / Bad 111
- “자동–수동 일치율: 45.6%” → 임계값·가중치 보정 후 상향
- 보정 정책(R3 반영)
- Retrieval TopScore 임계값 조정(예: ≥20=Good 후보)
- Retrieval 성공 시 CTA 필수 부착, Fallback에도 고객센터 CTA 제공
- 부분매칭 Good는 Gold 데이터 보강하여 업데이트
→ 위 보정 이후, 본문 상단 최종 평가 표의 기준으로 품질을 점검·정리했습니다.

Part 4. RAG + Rule 하이브리드
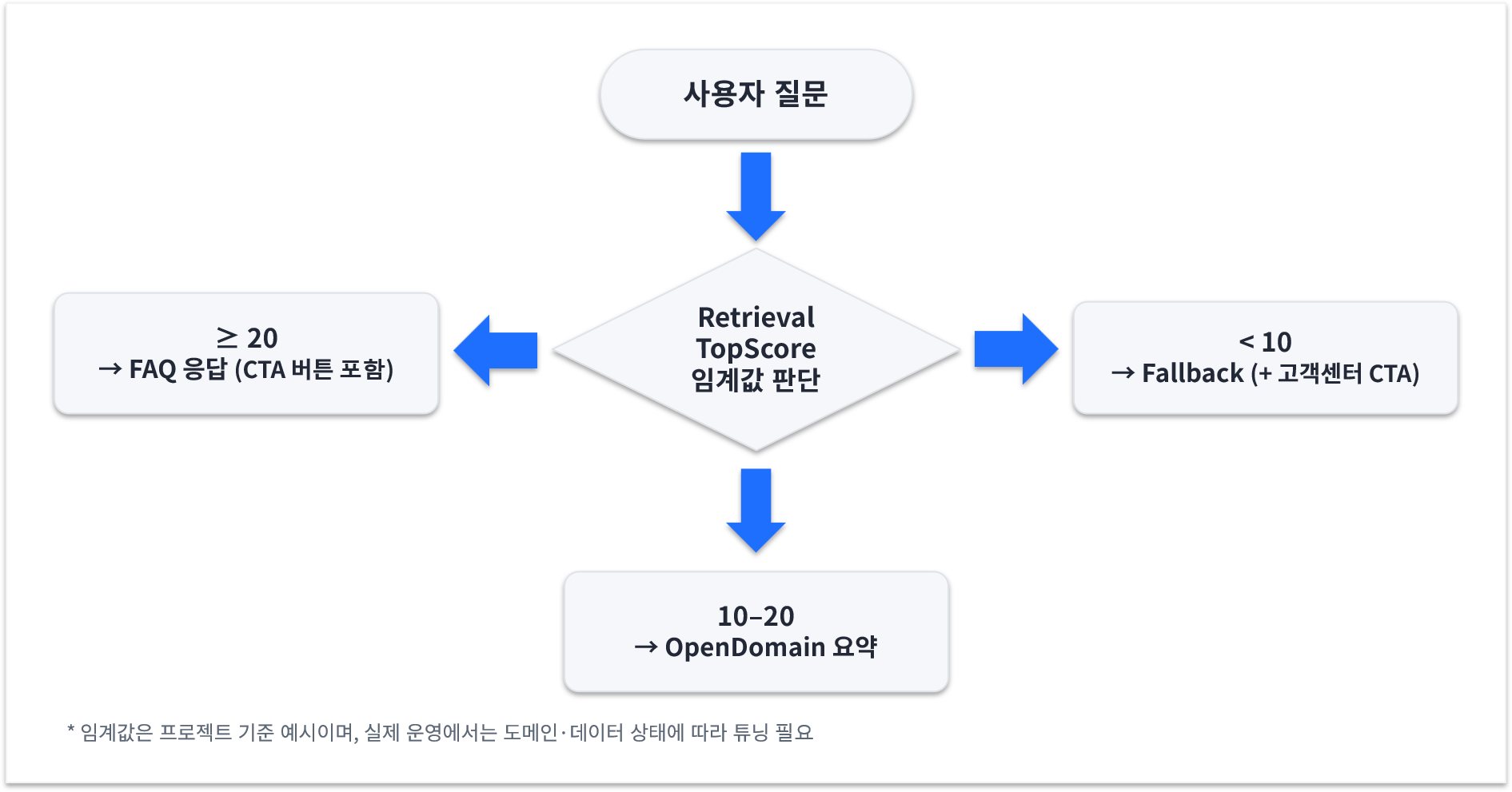
- 현업에서는 Rule-first를 반영했으나, 본 프로젝트에서는 RAG-first를 도입하여 실험
- Retrieval 신뢰도(TopScore/Threshold)에 따라 FAQ → OpenDomain → Fallback으로 분기 처리
- 역할 분리: “Rule = 안정성”, “RAG = 커버리지·설명력”
※ Vercel 배포 환경에서는 런타임(Edge vs Node) 및 경로 처리 차이로 인해 일부 질의(띄어쓰기, 유사명칭 등)의 검색 인식률이 Stackblitz 실험 환경 대비 다소 낮게 나타났습니다. 코드 구조와 데이터는 동일하며, 이는 환경 특성에서 비롯된 결과로 판단됩니다.
Part 5. 배포 트러블슈팅

- Vercel 환경: OpenAI 직접 호출 지양 → /api/chat.ts 에지 프록시
- 인덱싱 race 방지: ensureRagReady() 싱글톤 초기화 + 임베디드 코퍼스
- dev/prod 코퍼스 동기화: assets 임베드 + 런타임 /faq.json 덮어쓰기
- 재할당 경고 해결: const → let
- 공식 FAQ URL 변경: 리다이렉트 미지원 건은 외부 이슈로 Skip
3️⃣ 결과 & 배운 점 (What / Lessons)
🎯 핵심 성과
- 최상단 최종 평가 표 기준으로 정확도·라우팅/폴백·링크/CTA·성능·스타일/안전·UI/UX 전 항목 Pass를 달성했습니다.
- Rule + RAG 결합 구조를 구축하고, 자동 QA 루틴(runBatch)을 적용했습니다.
- R1→R2→R3 개선 사이클을 통해 품질을 확보하고 프로덕션 레디 수준으로 정비하였습니다.
🧩 진행 중 어려움
- 마지막 5% 완성 구간에서 시간 소요가 집중되었습니다. (체감상 전체 소요 시간의 20% 이상)
- 공식 사이트 URL 변경(리다이렉트 미지원)로 일부 항목은 Skip 처리했습니다.
- 바이브 코딩 시, 프롬프트 반복 입력 시 맥락을 벗어나 필요 이상으로 수정 발생하는 케이스가 많았습니다.
- 배포 환경(Vercel)에서 RAG 검색 성능이 Stackblitz 대비 약하게 나타났습니다. 이는 런타임 및 빌드 환경 차이로 인한 현상으로, 실 서비스 영향 범위는 RAG 한정으로 나타났습니다.
💡 교훈
- 작업 단위는 최대한 작게 쪼개고, 문맥은 명확하게 가져가야 합니다. (챗방 최대한 쪼개기 + 상세한 프롬프트 필요)
- 제안 코드는 그대로 적용하기보다 구조를 확인하고 최소 수정으로 해결해야 합니다.
- 바이브 코딩은 개발 도구에 가깝습니다(기본 문법·구조 이해가 효율을 좌우).
- Agent 로 자동 검수 + 수동 QA 조합으로 효율적으로 시간을 아끼고 품질을 높여줍니다.
- 초기 목표는 50% 범위로 설정해야 합니다. 최초 예상보다 2~3배의 시간과 노력이 소요되기 쉬워, 단계별 확장이 현명합니다.
- RAG 보정은 생각보다 어렵습니다. (예: 유사 발화·띄어쓰기·별칭 대응 등)
P.S. 추석 연휴 내내 작업하여 마지막 보정 작업과 글 작업을 진행하니 어느덧 1주일이 금방이네요. 처음 해보는 바이브코딩은 생각보다 어렵고 힘들었지만, 생각보다 재미있고 많은 걸 배울 수 있었습니다. 더 재미나고 쉬운 바이브코딩 2탄으로 찾아오겠습니다 😊🤩

